多值字段
综述
除了简单标量数据类型之外,JSON还具有空值、数组和对象,炎凰数据平台都已支持。多值字段是由零个或零个以上的值组成的有序列表,当输入字段包含一组数值而不是单个值(例如,JSON数组或包含一个或多个listDelimiter字符的TSV字段)时,会生成这些值。
炎凰数据平台可以支持多值字段的存储和查询,但目前不支持嵌套的多值结构及多值字面常量。
JSON数据类型的解析
字段抽取——扁平化处理
JSON原生数据类是键值对(字典或者关联数组)。在平台中对JSON的数据的解析会将所有嵌套的键值对抽取字段扁平化处理,不会存在嵌套的数据结构,但会存在多值数组类型。例如对于下面的JSON数据事件:
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devils Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" }
],
"tags": ["donut", "cake"],
"others": [
{
"remarks": [
"foo", "bar"
]
}
]
}
平台会抽出下列字段:
"id": "0001"
"type": "donut"
"name": "Cake"
"ppu": 0.55
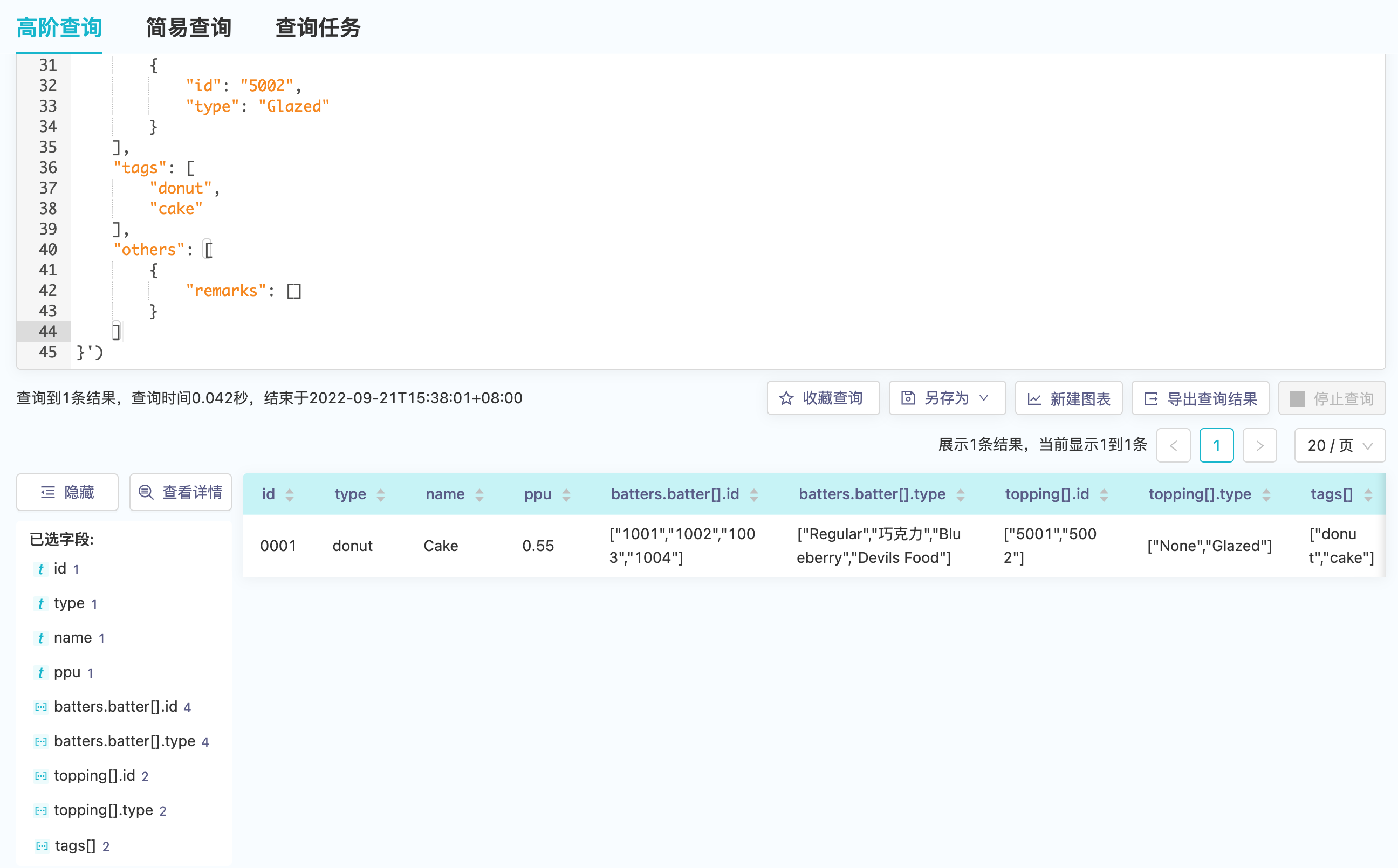
"batters.batter[].id": ["1001", "1002", "1003", "1004"]
"batters.batter[].type": ["Regular", "Chocolate", "Blueberry", "Devils Food"]
"topping[].id": ["5001", "5002"]
"topping[].type": ["None", "Glazed"]
"tags[]": ["donut", "cake"]
"others[].remarks[]": ["foo", "bar"]
平台将所有层级打平,变成单层的键值对,除了简单的标量数据类型之外,会添加多值数组类型,层级结构用"."来表达,同时对于数组结构的键,会加上"[]"以区分简单数据类型。通过parse_json函数可以展示出相应结果:
SELECT * FROM parse_json('{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devils Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" }
],
"tags": ["donut", "cake"],
"others": [
{
"remarks": [
"foo", "bar"
]
}
]
}')
配置JSON数据格式的字段抽取
在平台的数据目录中,预置了数据源类型json,代表索引阶段的JSON数据字段抽取,用户也可以自定义查询阶段字段抽取。
- 索引阶段
- 查询阶段 详见: 字段抽取
也可以配置自己的数据源类型做json数据抽取,但不建议同时配置索引和查询阶段,这样每个抽取字段会出现两遍且内容相同。
在查询中使用多值字段
过滤
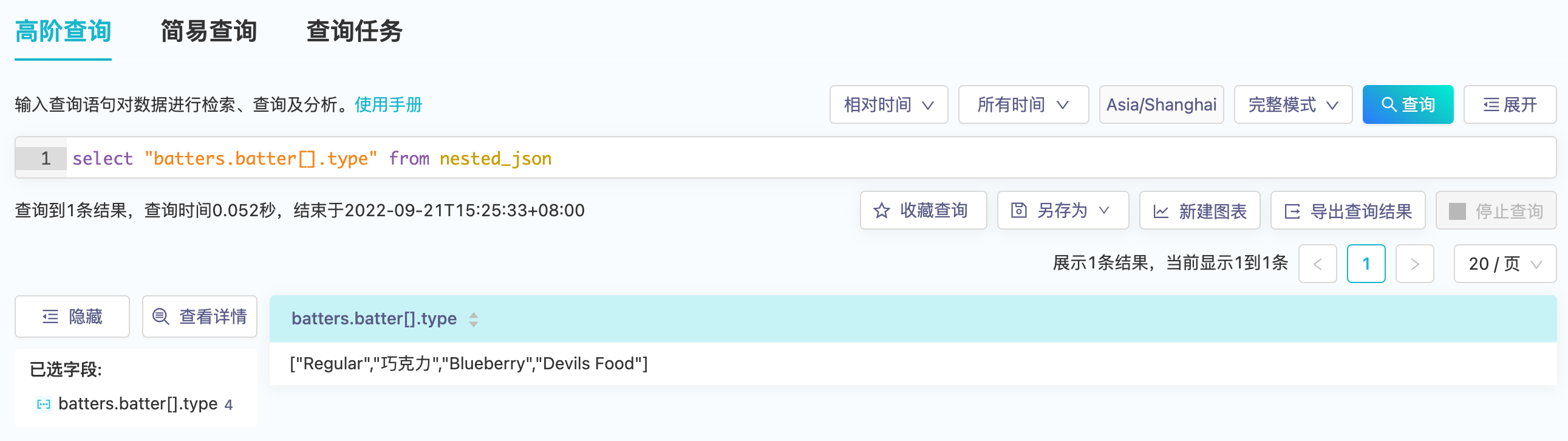
平台添加了array_contains(mv_expr, element_expr)来辅助过滤多值字段,其中mv_expr的输出类型为多值类型,element_expr为多值字段中元素类型。以下的样例数据集nested_json包含了三条json数据。
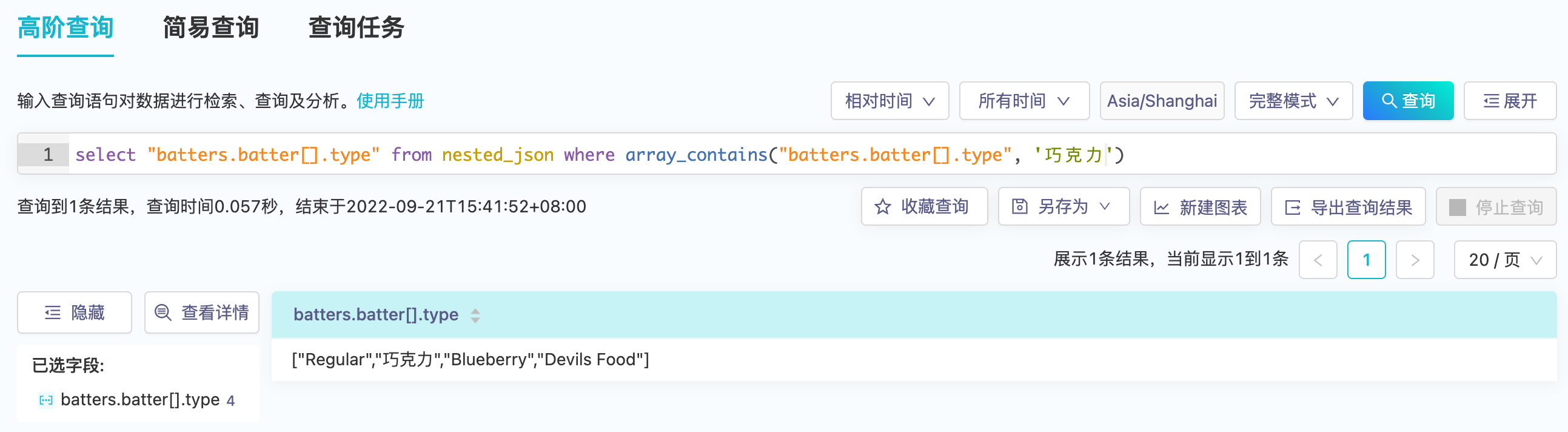
- 使用
array_contains(field_name, 'element')来过滤- 过滤前(由于多值字段)
- 过滤后
- 过滤前(由于多值字段)
- 使用
array_contains(field_name, field_name)来过滤- 过滤前
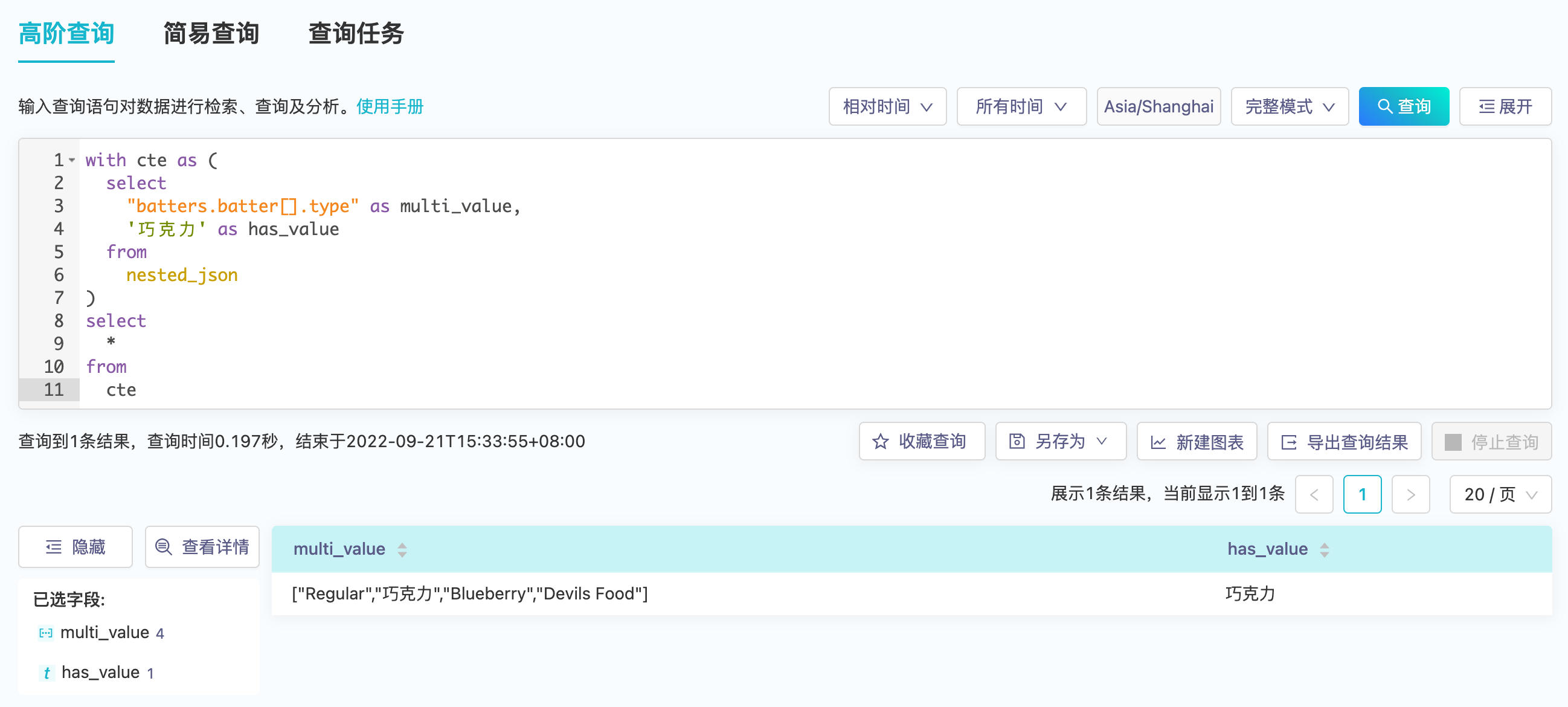
- 过滤后
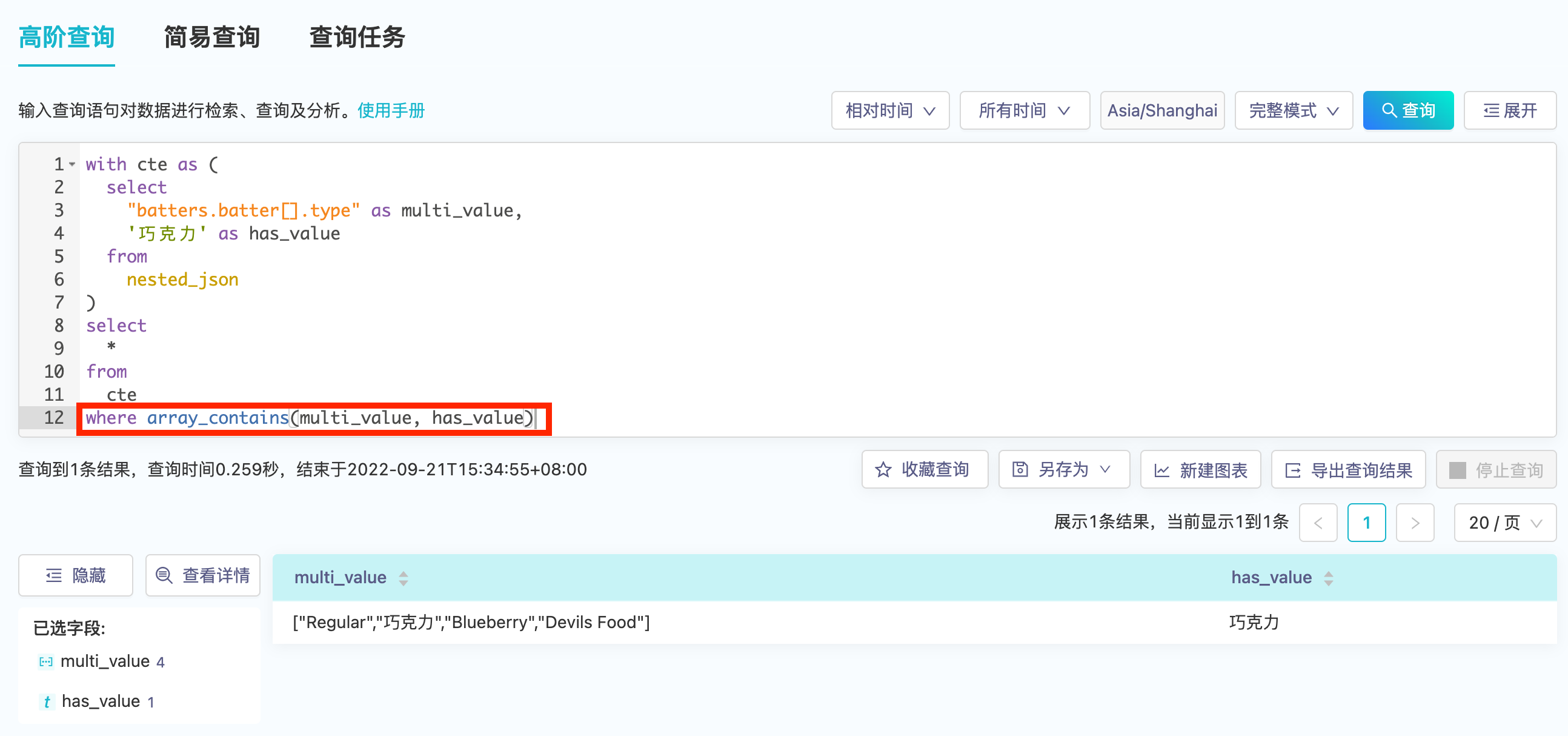
- 过滤前
计算
平台提供了flatten(field_name)表函数来展开多值字段:
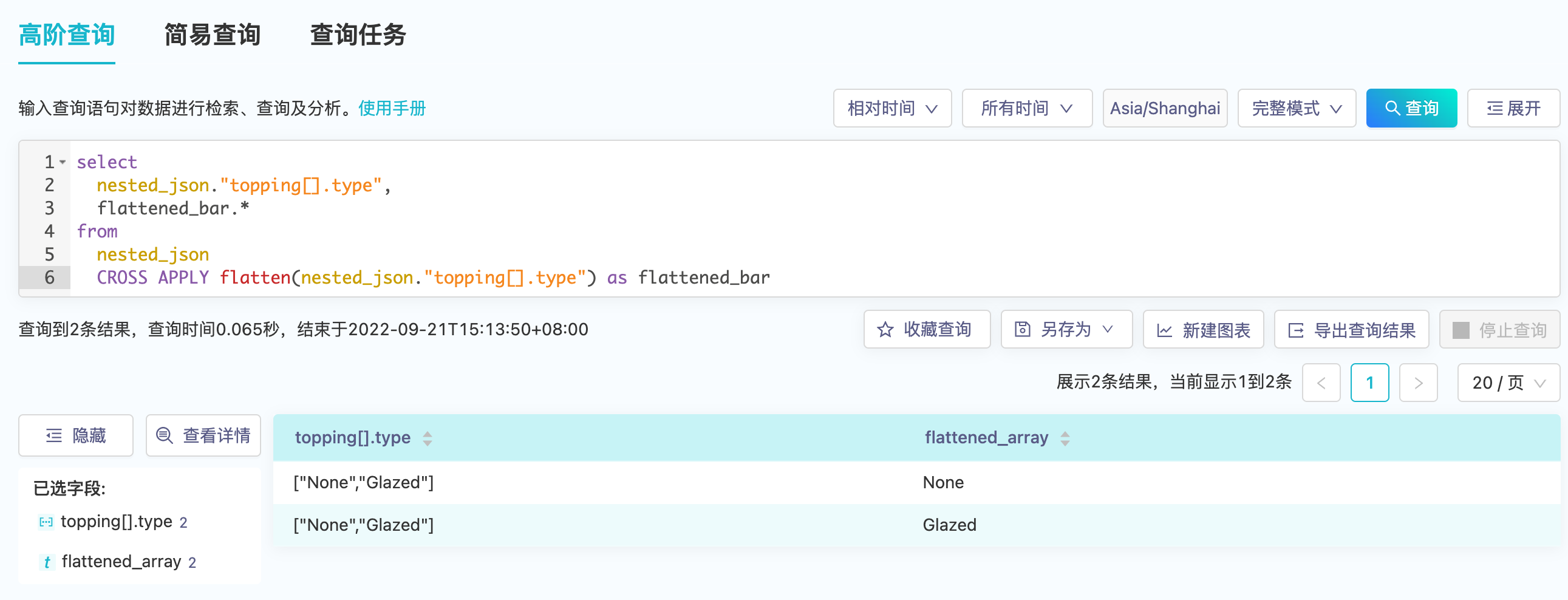
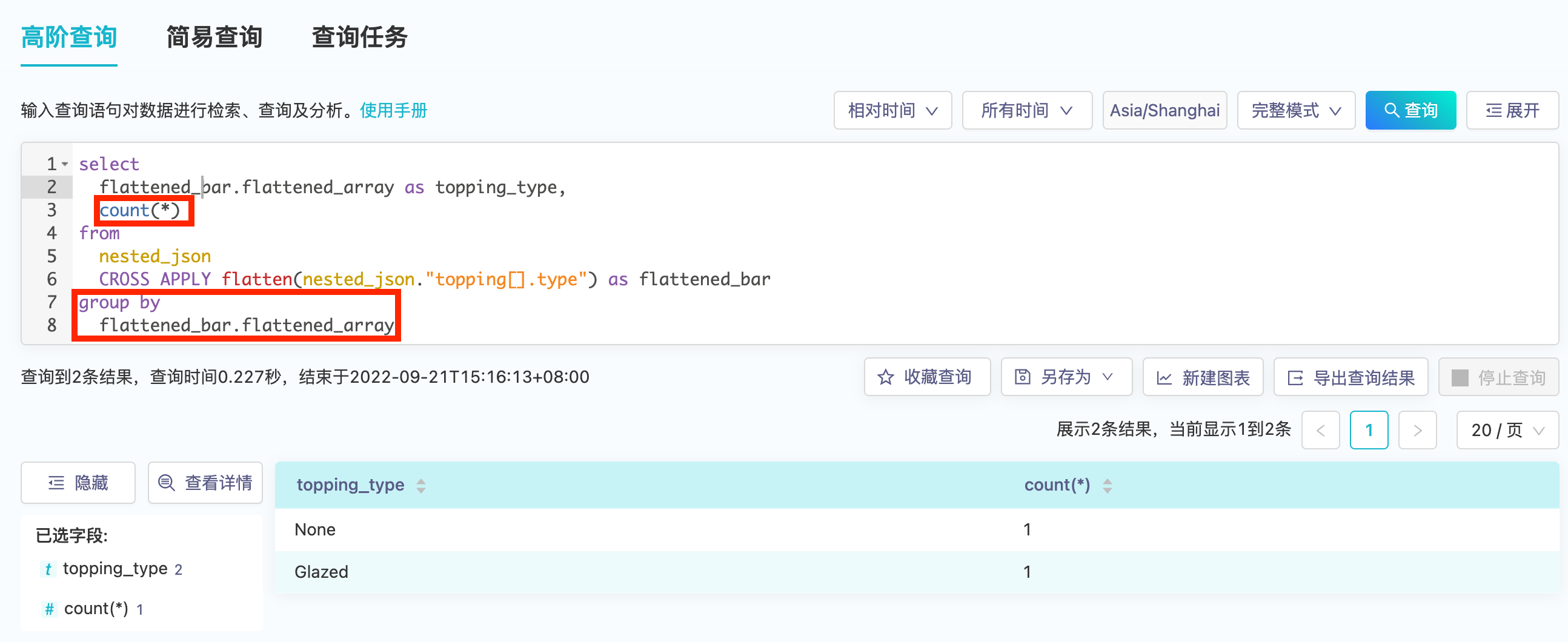
将多值字段展平后,我们就可以对展平后的字段做分组聚合计算,或其他标量计算:
查询中解析JSON字符串
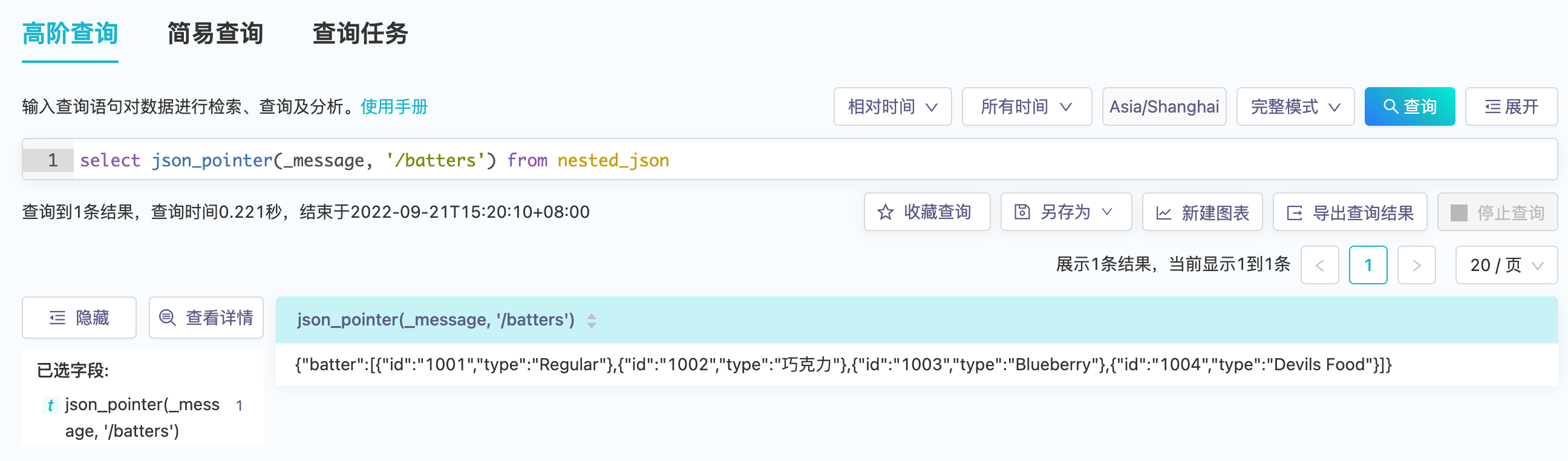
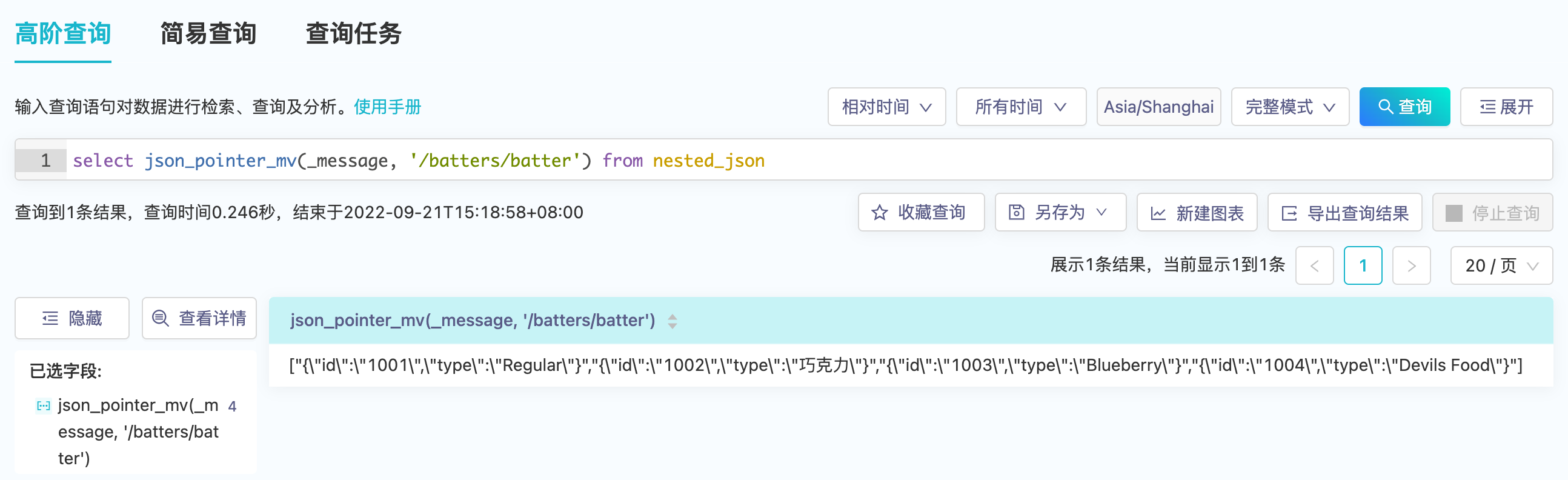
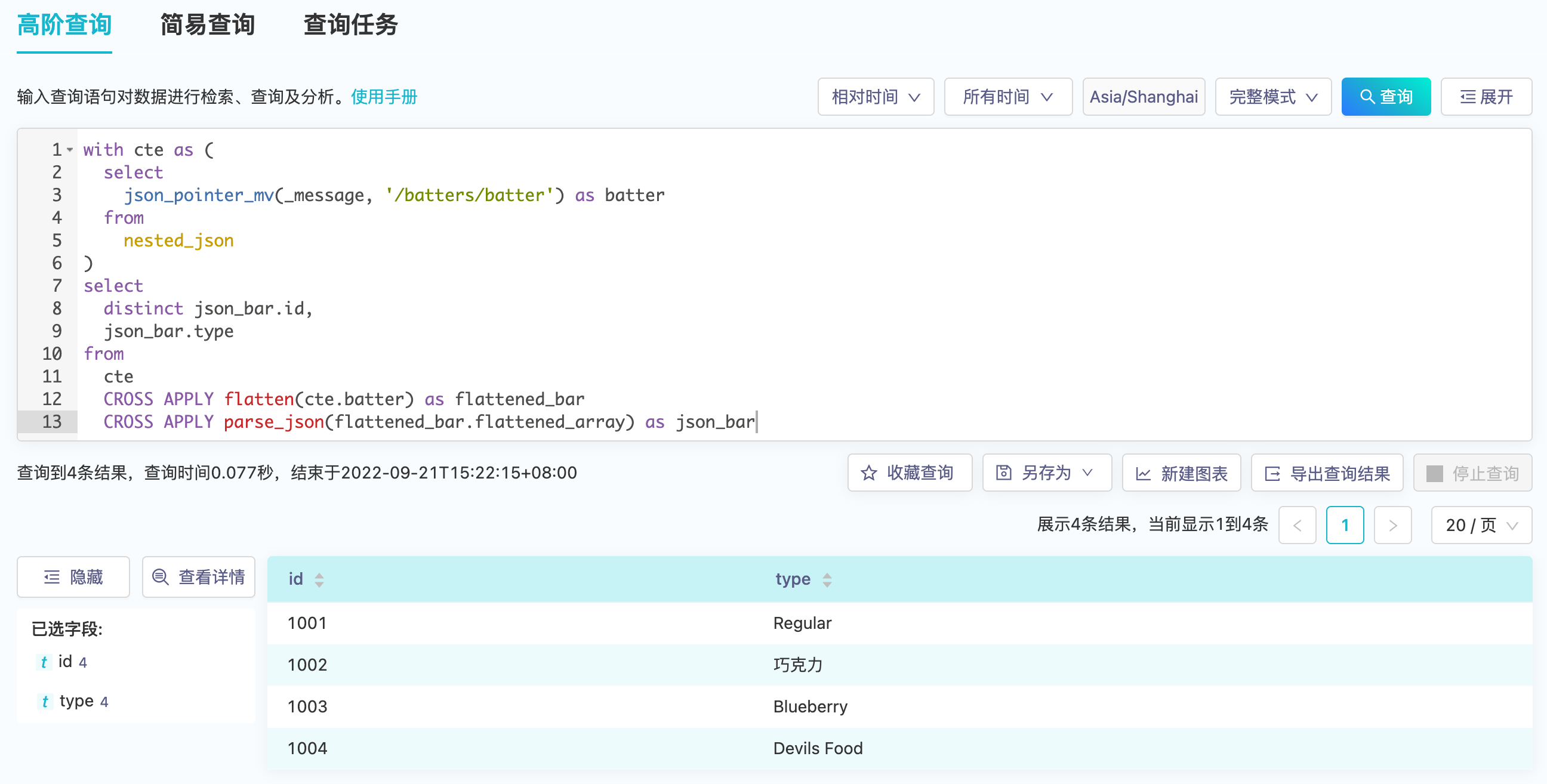
对于JSON数据的字段抽取,{ "id": "1001" }和{ "type": "Regular" }的关联性将会丢失,虽然当前平台多值字段是一组有序值,但也难以用两个多值字段的有序性来表达关联性,因而平台提供了标量函数json_pointer(json_string, json_pointer_path)和json_pointer_mv(json_string, json_pointer_path)来得到关联性,两者输入都为字符串类型,不同的是json_pointer输出为字符串,json_pointer_mv输出为多值字符串类型。
JSON Pointer是标准化(RFC6901)在JSON文档中选择值的方法,合法的路径有:
| JSON Pointer路径 | 健值 |
|---|---|
| /foo | json_document["foo"] |
| /foo/0 | json_document["foo"][0] |
| / | json_document |
| /a~1b | json_document["a/b"] |
| /m~0n | json_document["m~n"] |
| /c%d | json_document["c%d"] |
| /e^f | json_document["e^f"] |
| /g|h | json_document["g|h"] |
| /i\j | json_document["i\j"] |
| /k\"l | json_document["k\"l"] |
| / | json_document[" "] |
空的Json Pointer
""会解析出整个JSON
示例:
select json_pointer_mv('[1, 2, 3]','') as root
上述查询会得到如下结果: |root| |:----| |["1","2","3"]|
其它示例:
json_pointer
json_pointer_mv
找到关联关系
多值字段索引
在平台中,对多值字段会对单个元素做索引,因而array_contains(field, 'element')可以利用索引加速查询。