物化视图
时序数据比如日志、指标数据、传感器数据一般大量并且持续不断。物化视图提供了一种方式,使得时序数据的数据集能够根据用户提供的查询条件,进行部分预计算,从而达到加速查询的目的。和大多数据库物化视图有所不同的,炎凰数据中的物化视图能提供实时数据的计算结果,用户无需关心物化视图预计算导致的延迟问题。同时,如果之前导入的数据进行了更新或者删除,物化视图引擎能够自动维护数据一致性,保证输出结果的精确。
物化视图的典型应用场景包括:需要对查询作出快速响应,而又需要耗费长时间获得结果。
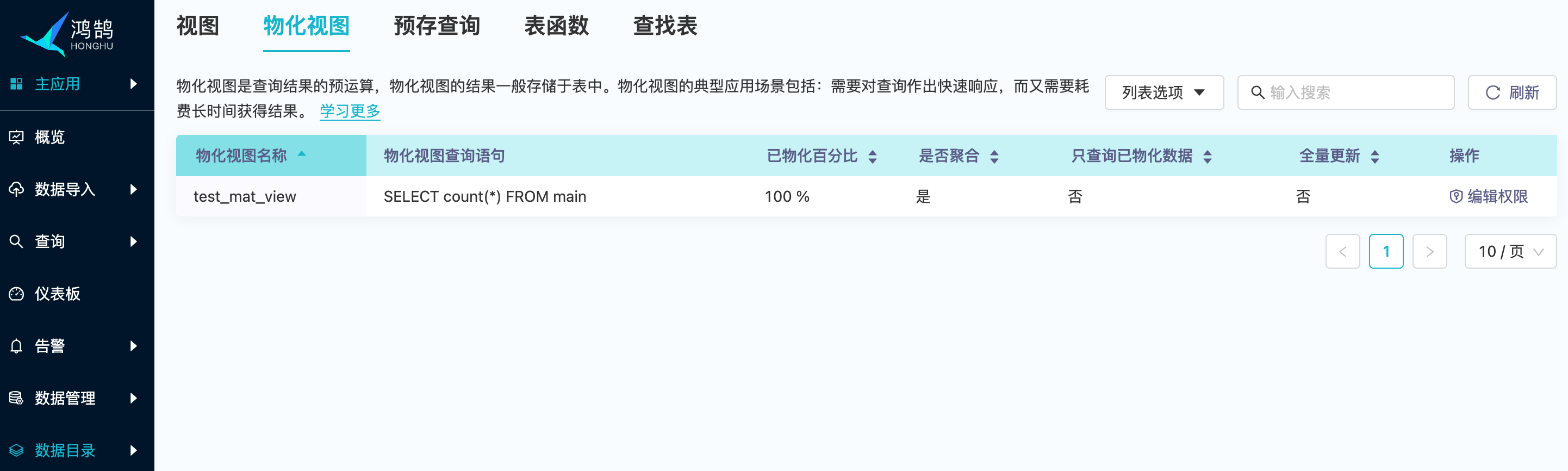
物化视图管理页面
物化视图页面可以查看和刷新物化视图列表,创建、更新和删除物化视图只能通过 SQL 来进行管理操作。
用户接口
炎凰数据平台目前只提供 SQL 查询语句创建物化视图。查询语句包含CREATE和DROP, 由于物化视图包含预计算数据,不支持UPDATE操作。
物化视图管理 SQL 语法
CREATE MATERIALIZED VIEW <view_name>
[
WITH ( MATERIALIZED_ONLY = false,
TIME_BUCKET = '1h')
]
AS <materialized_view_statement>
(WITH (NO)? DATA)?
物化视图提供了可配置参数:MATERIALIZED_ONLY和TIME_BUCKET,并且可以通过WITH NO DATA指示创建物化视图是否需要计算历史数据的物化结果。
MATERIALIZED_ONLY
默认值为false,物化视图引擎能够自动维护数据一致性,保证数据结果的准确性,和基于原始数据集的查询结果保持一致。在查询物化视图时,查询结果包含两部分:1)已预计算物化数据;2)未物化的数据会在原始的数据集上进行计算返回。如果设置MATERIALIZED_ONLY = true,则只查询第一部分数据。未物化的数据主要包含内存中的数据,这部分数据不会实时物化,某些场景下,用户可以接受数据结果非实时准确性,可以考虑通过使用MATERIALIZED_ONLY = true选项创建物化视图以提供更好的查询性能,此时未物化的实时数据会被忽略,仅提供已经物化的数据的计算结果。
TIME_BUCKET
聚合是一段时间内原始数据的汇总,物化结果的时间粒度由TIME_BUCKET控制,默认是1h。您可以选择d(天)/h(时)/m(分)作为时间单位。TIME_BUCKET 将影响物化数据的大小,以及查询的时间粒度。
WITH NO DATA
物化预计算查询数据会带来一定的开销,时序数据集会随着时间累计数据量,如果您创建物化视图时并不关心过去的历史数据,可以设置WITH NO DATA。默认为WITH DATA,这意味着,平台默认会将数据集上的历史数据全部进行预计算物化。
视图查询语句
物化视图引擎能够自动维护数据一致性,是基于导入时间进行数据分片后,逐步增量预计算分片数据的查询结果。因此视图查询语句的原则是能够支持并行计算,那么对查询语句有一些限制:
- 当前版本仅支持单数据集(Event Set)的查询语句,暂不支持 join 表达,也不支持
event_set_1 | event_set_2多数据集的表达 - 不支持嵌套的物化视图,但支持基于普通视图创建物化视图
- 不支持
ORDER BY语句 - 不支持
LIMIT语句 - 不支持窗口函数语句
- 不支持
DISTINCT表达 - 不支持不能并行计算的聚合函数,目前支持的聚合函数有:
SUM/COUNT/MIN/MAX/AVG - 不支持嵌套的聚合表达,如
SELECT SUM(orders) FROM (SELECT COUNT(item) as orders FROM sales GROUP BY boutique),此查询有两层聚合逻辑,无法对最外层聚合表达直接进行并行计算 - 聚合函数中不支持
DISTINCT表达 - 物化视图中使用的函数必须是确定性的,不支持
NOW(),DATE_ADD(time_unit, time_delta)标量函数,也不支持随机函数RANDOM()。
示例
非聚合物化视图
查询少量列和行
CREATE MATERIALIZED VIEW my_view AS (
SELECT item, order_time
FROM sales
WHERE boutique = 'yhp'
)
实时聚合的物化视图
CREATE MATERIALIZED VIEW my_view
AS (
SELECT SUM(revenue) as total_revenue, COUNT(*)
FROM sales
GROUP BY boutique
)
仅物化新数据不物化历史数据
CREATE MATERIALIZED VIEW my_view
AS (
SELECT SUM(revenue) as total_revenue FROM sales
)
WITH NO DATA
仅查询物化的数据
CREATE MATERIALIZED VIEW my_view
WITH (
materialized_only = true
)
AS (
SELECT SUM(revenue) as total_revenue FROM sales
)
设置聚合物化的时间粒度
CREATE MATERIALIZED VIEW my_view
WITH (
time_bucket = '30m'
)
AS (
SELECT SUM(revenue), AVG(revenue) as total_revenue FROM sales
)
删除物化视图
DROP MATERIALIZED VIEW <view_name>
查询物化视图
SELECT * FROM <view_name>
列出物化视图状态
SHOW [FULL] MATERIALIZED VIEWS
SHOW FULL MATERIALIZED VIEWS where name = 'test_mv'
实时聚合物化视图
聚合是一段时间内原始数据的汇总,可以用来统计每天的平均温度、每 5 分钟的最大 CPU 利用率以及每天网站上的访问者数量等场景。聚合查询统计计算是需要处理大量数据的计算密集型任务。此外,由于计算资源在两个资源密集型进程之间被分割,同时读取数据集和计算聚合可能导致读取速率的减慢。实时聚合物化视图解决了这两个问题。
实时聚合物化视图会自动刷新物化视图,因此它们大大加快了需要处理大量数据的工作负载。与其他数据库不同,炎凰数据平台物化视图在添加新数据或修改数据时(Delete Events),物化引擎会在后台自动刷新预计算物化结果集,并允许您像检索任何其他数据集一样检索结果,保证数据结果的实时准确性。
连续聚合加速了仪表板和可视化,汇总了高频率采样的数据,并在长时间内查询了下采样的数据。炎凰数据平台实时聚合物化视图下采样时间粒度为1 小时,目前默认所有实时聚合物化视图的下采样粒度都是1 小时,用户可以在创建物化视图的时候配置TIME_BUCKET选项自定义采样时间粒度。聚合物化视图的下采样粒度1 小时意味着在查询实时聚合物化视图时,只有时间范围大于1 小时才可能使用物化结果进行加速。
物化结果加速时间范围
炎凰数据平台数据集(Event Set)是以事件(Events)导入时间进行数据分片的,物化视图引擎将对每个数据分片逐一进行预计算物化操作。预计算下采样时间粒度为1 小时,是以事件(Events)本身的时间进行统计计算的。事件的时间和导入时间可以不相关。在查询物化视图的时候,会将时间范围按照1 小时划分时间桶(Time Bucket),查询结果由三部分组成:
- 对于未物化的数据分片,直接在原始数据集上执行视图查询
- 对于已物化的数据分片,且完整的时间桶,直接采用已经物化的数据分片预计算结果
- 对于已物化的数据分片,且不完整的时间桶,需要在原始数据集上重新执行视图查询
将上述三部分数据汇总就得到了当前时间范围内准确的物化视图查询结果。

由于实时聚合物化视图默认下采样的时间粒度为1 小时,当查询时间范围没有完整的时间桶(Time Bucket)时,查询将重新在原始数据集(Event Set)上执行视图查询。当物化视图查询含有大量数据事件,但集中在 1 小时内,不适用物化视图进行加速。目前 平台将提供可配置的下采样时间粒度参数TIME_BUCKET。
实时非聚合物化视图
不同于实时聚合物化视图,非聚合物化视图时间粒度保持与原始数据集一致,不存在时间粒度的差异,查询结果包含两部分:
- 对于未物化的数据分片,直接在原始数据集上执行视图查询
- 对于已物化的数据分片,直接采用已经物化的数据分片预计算结果 将上述两部分数据汇总就得到了当前时间范围内准确的物化视图查询结果。
何时需要物化视图
物化视图适用在以下场景:
- 查询结果包含相对于定义中原始数据集(Event Set)的少量行或列
- 查询结果包含需要大量处理的结果:
- 半结构化数据分析
- 需要很长时间计算的聚合
- 视图的原始数据集(Event Set)不经常更改,目前仅提供
Delete Events的更改操作 - 查询位于外部表,例如 JDBC 查询结果,但不能自动更新外部表查询,暂时也不支持手动更新外部表查询的物化结果
炎凰数据平台对物化视图的实现提供了许多独特的特性:
- 物化视图可以提高重复使用相同子查询结果的查询的性能
- 物化视图由物化引擎自动透明地维护。后台服务在原始数据集(Event Set)导入新数据和更改数据后自动触发更新物化视图。这比在应用程序级别手动维护物化视图的等价物更有效,也更不容易出错
- 无论原始数据集(Event Set)导入了多少新数据或者更改了数据,通过物化视图访问的数据总是最新的。物化视图未完成的数据分片预计算结果,将从基表中检索任何所需的较新数据