采集Kafka数据
炎凰数据平台内置了采集Kafka数据的功能,用于采集外部Kafka系统中的数据。
数据源导入数据
- 进入炎凰数据平台,将鼠标移到左侧"数据管理"图标
 , 选择”采集Kafka数据”,进入页面。
, 选择”采集Kafka数据”,进入页面。
创建Kafka数据源
步骤:
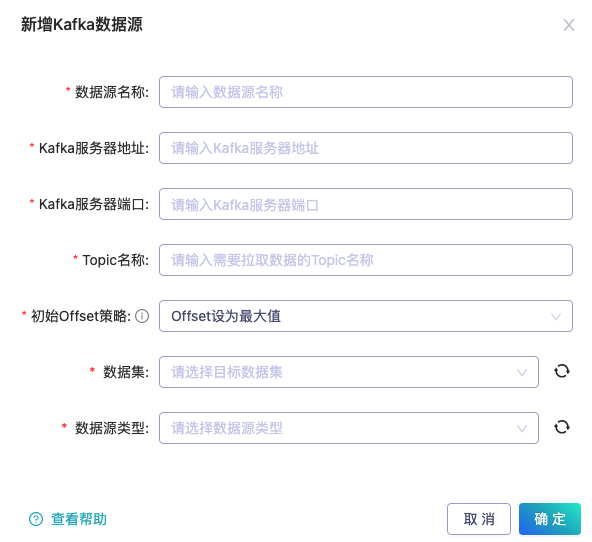
- 点击新增外部数据源,选择Kafka数据源。
- 填入对应属性。
- 创建完连接器后,可以点击
查询数据按钮来查询导入数据
信息
在创建 Kafka 数据源时,可以设置导入数据时的 “初始 Offset 策略 ”,灵活的指定不同的Kafka Topic 数据导入方案。
- Offset 设为最小值:从 topic 的最开始导入数据。
- Offset 设为最大值:从 topic 的最末尾导入数据。
默认从 topic 最末尾导入数据。
编辑数据源
步骤:
- 点击表格中右侧的
编辑按钮来编辑一个已经建好的数据源。
复制Kafka数据源
步骤:
- 点击表格中右侧的
复制按钮来复制一个已经建好的Kafka数据源。
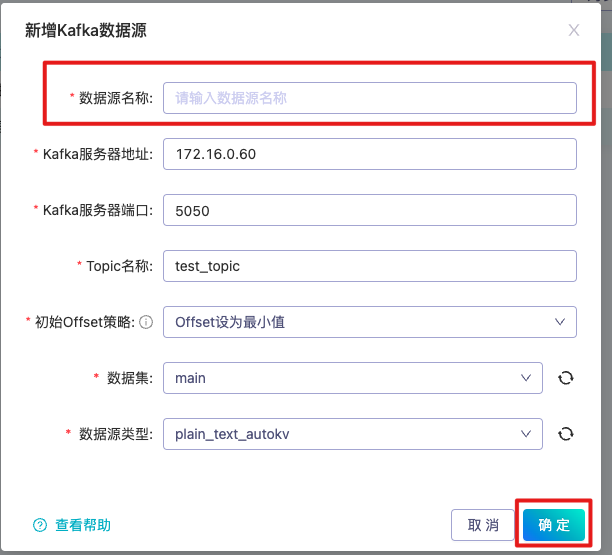
- 在打开的新建数据源模态框中,默认为复制连接器的所有配置。需要填入复制的Kafka数据源的名称,按需更改相应的连接器配置参数。点击确定,创建新的Kafka数据源
删除Kafka数据源
步骤:
- 点击表格中右侧的
...按钮,在菜单中点击删除按钮来编辑一个已创建好的数据源
信息
使用kafka导入数据时,对于使用数据源类型进行字段抽取,有一定限制:
- 自定义ingestion time数据源类型:暂不支持自定义ingestion time数据源类型的字段抽取,因此配置的
ingestion_time_extraction、ingestion_time_field_names数据源类型属性,在通过kafka导入数据时无法生效。 - csv数据源类型:暂不支持对csv数据源类型的字段抽取,对于导入的数据指定
_datatype为csv将无法生效。 - 多行文本合并: 暂不支持导入时做多行文本合并,对于导入的数据,配置的
firstline_format数据源类型属性将无法生效。 - 丢弃
_message字段: 暂不支持导入时对_message字段做丢弃处理,对于导入的数据,配置的discard_raw_message数据源类型属性将无法生效。