表函数 ( Table Function )
不同于标量函数,表函数的返回值是一个数据行(Row)的集合,这个集合表示一个二维表结构。 普通的标量函数的返回值是一个标量值(Scalar Value)。
SQL表函数
SQL表函数可以看成是一个带参数的视图(Parameterized View),支持用户定义函数(User Defined Table Function, UDTF)。
SQL表函数操作语法如下:
-- 创建表函数
CREATE [ OR REPLACE ] FUNCTION
function_name ( [ named_parameter ]* ) [RETURNS return_type]
AS query_expression
-- 删除表函数
DROP FUNCTION function_name( [signature])
-- 列出表函数
SHOW FULL FUNCTIONS where return_type = 'TABLE'
named_parameter由@<parameter_name> <parameter_type> [default|= <default_value>]组成, 目前支持的参数类型有:TABLE(表值参数),STRING,INT,FLOAT,BOOL,参数列表可省略,参数默认值可省略- 当用户自定义表函数时,返回类型
return_type应该申明为TABLE,当返回类型没有额外申明的时候返回类型默认为TABLE - 允许创建同名不同参数个数列表的表函数,但不支持同名函数,同样参数个数,不同参数类型的表函数,这主要源于系统可以自适应转换数据类型
- 删除表函数定义时,需要指定函数签名(signature)。如果只有一个同名函数的话,暂时也不支持省略参数列表。如果删除时给了正确的参数个数,但是类型不匹配的话系统将报错提示
- 使用函数列表的默认值时,使用关键字
DEFAULT替代
样例:
定义SQL表函数,从
data_set中查找包含关键字key的事件。CREATE FUNCTION get_events_from_dataset(@data_set table, @key string)
AS ( SELECT * FROM @data_set WHERE CONTAINS(@key) )
SELECT * FROM get_events_from_dataset(main, 'GET')
DROP FUNCTION get_events_from_dataset(table, string)定义带
default值的SQL表函数CREATE OR REPLACE FUNCTION default_table_tf(@data_set table default main) AS select * from @data_set
select * from default_table_tf(default)
drop function default_table_tf(table)
定义同名SQL表函数
CREATE FUNCTION nested_tf(@data_set table) AS
select * from @data_set
CREATE FUNCTION nested_tf(@data_set table, @key string) AS select * from nested_tf(@data_set) where contains(@key)
select * from nested_tf(main)
select * from nested_tf(main, 'GET')
DROP FUNCTION nested_tf(table, string)
DROP FUNCTION nested_tf(table)
定义多个default参数
CREATE OR REPLACE FUNCTION multi_default_val_tf(@key string = 'GET', @data_set table, @limit int default 1)AS (SELECT * FROM @data_set where contains(@key) limit @limit)
select * from multi_default_val_tf(default, main, default)
drop function multi_default_val_tf(string, table, int)
参数列表不匹配时,报错提示
SELECT * FROM ip_location()
Table function undefined: 'ip_location' with 0 parameter(s), do you mean ip_location(STRING)
在炎凰数据平台中,SQL表函数作为表来源时,输入参数仅支持字面常量(Literal Value)或表值参数(Table-valued parameters)
表值参数(Table-valued parameters)
当parameter_type为TABLE时,该参数为表值参数(Table-valued parameters),简称TVP。
在查询语句中,目前表值参数只支持传入表名,不支持表函数等复杂表达,可以通过CTE查询名替换复杂表达。
非SQL表函数
炎凰数据平台提供了一系列非SQL表函数,用于丰富查询的内容,见预定义的非SQL表函数(Prebuilt Non SQL Table Function)。当前仅支持用户自定义Python函数(Python User Defined Table Function, Python UDTF)。自定义Python表函数,参见 Python UDTF开发。
创建删除自定义Python表函数,语法支持如下:
CREATE [OR REPLACE] FUNCTION <function_name>
LANGUAGE PYTHON
PACKAGE <package_path>
DROP FUNCTION <function_name>
LANGUAGE PYTHON
- 语法很简洁,所以需要用户在自定义时,将函数相关的信息及签名放在函数包中
package_path目前仅支持Eggfarm开发的函数打包上传的文件
样例:
创建新的python udtf
CREATE FUNCTION my_func
LANGUAGE PYTHON
PACKAGE 'my_func_table_func.tar.gz'查询python udtf
SELECT * FROM my_func(2, 'abc', 34)
SELECT * FROM my_func(3, 'def', 23, true)
SELECT * FROM my_func(4, 'opq', 82, false, 3.1415)删除python udtf
DROP FUNCTION my_func
LANGUAGE PYTHON
预定义的非SQL表函数
generate_series
c++ table function函数签名:
generate_series(start, end, step)函数参数:
- 参数类型:
(int, int, int) - start: 数值范围的开始(包含)
- end: 数值范围的结束(包含)
- step: 步长,可省略,默认为1
- 参数类型:
功能:根据给定的参数的范围和步长,生成一个只有一个数值字段的表。字段名为
generate_series样例:生成从1到10的10个整数,每个整数是一行。
SELECT * FROM generate_series(1, 10, 1)generate_series 1 2 3 4 5 6 7 8 9 10
ip_location
c++ table function函数签名:
ip_location(ipv4_address)函数参数:
- 参数类型:
(string) ipv4_address: ipv4地址,字符串表示的ipv4地址。
- 参数类型:
功能:根据给定的ipv4地址,查找ip对应的地理位置信息。每个ip地址查询返回如下五个字段。如果查不到信息,则返回null值。
country:国家region:区域province:省份city:城市isp: 运营商
样例:
查询单个ip地址的位置信息。
SELECT * FROM ip_location('43.228.180.166')country region province city isp country_en 中国 香港 china 通过
OUT APPLY算子丰富查询结果。输入的参数ip是一个字段。SELECT ip_table.*
FROM main
OUTER APPLY
ip_location(main.ip) AS ip_table
flatten
c++ table function函数签名:
flatten(multi_value_field)函数参数:
- 参数类型:
(multi value)
- 参数类型:
功能:将多值字段展平
样例:
展平多值字段
SELECT *
FROM parse_json('{"foo": ["bar1", "bar2", "bar3"]}') AS json_bar
CROSS APPLY flatten(json_bar."foo[]") as flattend_bar
| foo[] | flattened_array |
|---|---|
| ["bar1","bar2","bar3"] | bar1 |
| ["bar1","bar2","bar3"] | bar2 |
| ["bar1","bar2","bar3"] | bar3 |
parse
c++ table function函数签名:
parse(text, datatype)函数参数:
- 参数类型:
(string, string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)datatype: datatype的名称,或者是包含datatype名称的字段名。
- 参数类型:
功能:将
text对应的字符串使用datatype绑定的规则进行解析。样例:
对
_message字段使用_datatype字段包含的datatype名称关联的规则执行解析。SELECT parsed_table.*
FROM main
OUTER APPLY
parse(main._message, main._datatype) as parsed_table
parse_regex
c++ table function函数签名:
parse_regex(text, regex, max_match)函数参数:
- 参数类型:
(string, string, int) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)regex: 正则表达式,这个参数只能是一个常量字符串表达式。max_match: 可以匹配到的正则表达式的最大数量,默认为1. 当max_match=0的时候为无限制数量的匹配。
- 参数类型:
功能:将
text对应的值用regex指定的正则表达式匹配。如果能够匹配,并且正则表达式 当中有命名捕获组,则会将命名捕获组生成新字段。兼容PCRE格式的正则表达式。样例:
对常量字符串使用正则表达式匹配,得到新字段
a和bSELECT *
FROM parse_regex(
'this is a event to demo regex parsing table function',
'this is a (?<a>\w+) to demo (?<b>.*)'
)返回结果集:
a b event regex parsing table function 对
_message字段使用正则表达式解析,然后将解析得到的字段关联到原始表SELECT main._message, regex_table.ip
FROM main
OUTER APPLY
parse_regex(
main._message,
'(?<ip>\d+\.\d+\.\d+\.\d+)'
) AS regex_table返回结果集:
_message ip 107.173.176.148 - - [1... 107.173.176.148 157.55.39.8 - - [13/De... 157.55.39.8 109.169.248.247 - - [1... 109.169.248.247 特殊带有
_KEY_和_VAL_的字段会进行自定义字段抽取
SELECT *
FROM parse_regex(
'a=b c=d e=f user=name g=h',
'(?P<_KEY_1>\w+)=(?<_VAL_1>\w+) (?P<_KEY_2>\w+)=(?<_VAL_2>\w+)',
0
)返回结果集: | a | c | e | user | | ---- | ---- | ---- | ---- | | b | d | f | name |
parse_json
c++ table function- 函数签名:
parse_json(text, array_mode, max_depth) - 函数参数:
- 参数类型:
(string, string, int) text:待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)。array_mode:控制json中数组的解析行为,可选模式有merge_nested和flatten_nested,默认为merge_nested。max_depth:控制解析json的深度,默认值为-1,表示不限制。
- 参数类型:
- 功能:将
text对应的字符串使用json反序列化解析 - 样例:
- 对常量字符串使用json反序列化解析,得到新字段
a和b.
SELECT *
FROM parse_json('{"a": 123, "b": "hello-world"}')- 对
_message字段使用json反序列化解析,然后将解析得到的字段关联到原始表
SELECT tweets._message, parsed_message.*
FROM tweets
OUTER APPLY
parse_json(tweets._message) as parsed_message- 用
flatten_nested模式解析json,遇到值类型为数组的字段会停止展开,比如下面字段foo.bar的值类型为list<string>:
SELECT * FROM parse_json('{"foo":{"bar":[{"k1":"v1"}],"baz":"qux"}}', 'flatten_nested')foo.bar foo.baz ["{\"k1\":\"v1\"}"] qux - 对常量字符串使用json反序列化解析,得到新字段
parse_json_kv_table
c++ table function- 函数签名:
parse_json_kv_table(text) - 函数参数:
- 参数类型:
(string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)
- 参数类型:
- 功能:将
text对应的json字符串的第一层键值对解析成字段的值,分别对应key和value两个默认字段。 - 样例:
SELECT * FROM parse_json_kv_table('{"foo": {"bar": "baz"}}')
| key | value |
|---|---|
| foo | {"bar":"baz"} |
parse_autokv
c++ table function- 函数签名:
parse_autokv(text, separator) - 函数参数:
- 参数类型:
(string, string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)
- 参数类型:
- 功能:将
text对应的字符串使用kv结构的解析器来解析。text可以是一个用逗号或者空格分隔的kv结构,key和value的分隔可以是等号,value可以使用引号来表示引用。 2.separator: 自定义的键值分隔符,可省略,默认为= - 样例:
- 对常量字符串使用kv解析,得到新字段
abc和location
SELECT *
FROM parse_autokv('abc=123 location="china shanghai"')- 对
_message字段使用kv解析,然后将解析得到的字段关联到原始表
SELECT tweets._message, parsed_table.*
FROM tweets
OUTER APPLY parse_autokv(tweets._message) as parsed_table- 使用自定义键值对分隔符进行解析
SELECT *
FROM parse_autokv('abc: 123 location: "china shanghai"', ':') - 对常量字符串使用kv解析,得到新字段
parse_delimited
c++ table function函数签名:
parse_delimited(text, header, delimiter, quoter, trimming)函数参数:
- 参数类型:
(string, string, string, string, string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)header: text中每个value对应的头信息,用于指定字段名delimiter: 分隔符,可省略,默认是逗号,quoter: 引用符,可省略,默认是双引号",包含在引用符内的字符串不会被分隔符分割trimming: 移除字符串两侧的空白字符或其他预定义字符,可省略
- 参数类型:
功能:将
text对应的字符串使用分隔符解析。text可以是一个用delimiter作为分隔符的结构,value可以使用quoter来表示引用。样例:
- 对常量字符串解析,得到新字段
abc和location如下
SELECT *
FROM parse_delimited(
'123,china shanghai',
'abc,location'
)
-- 结果
-- abc location
-- 123 china shanghai- 对常量字符串解析,指定分隔符和引用符,得到新字段
abc和location
SELECT *
FROM parse_delimited(
'123$"china$shanghai"',
'abc$location',
'$',
'"'
)
-- 结果
-- abc location
-- 123 china$shanghai- 对
_message字段使用分隔符解析,然后将解析得到的字段关联到原始表
SELECT tweets._message, parsed_table.*
FROM tweets
OUTER APPLY
parse_delimited(
tweets._message,
'c1,c2,c3'
) as parsed_table- 使用trimming
SELECT * FROM parse_delimited(
'v1,$$v2$,v3',
'c1,c2,c3',
'',
'',
'$')
-- 结果
-- c1 c2 c3
-- v1 v2 v3- 对常量字符串解析,得到新字段
parse_csv
c++ table functionparse_csv是parse_delimited的一个别名。有类似的签名和同样的用法。
- 签名:
parse_csv(text, header, delimiter, quoter, trimming)
load_csv
c++ table function函数签名:
SELECT * FROM load_csv(path[, partitions, inspect_fragment_count, schema_conversion])函数参数:
- 参数类型:
(string, string, int, string, schema_conversion) path: 加载csv数据集的路径,可以是单个文件的路径,也可以是文件夹,文件必须放置于${STONEWAVE_HOME}/var/external_data文件夹路径下。partitions: 指定csv数据集的子目录为分区,例如year/month/day将会把目录结构为2020/11/16解析成为year=2020, month=11, day=16放在结果集中。inspect_fragment_count: 指定自动检测数据集模式(schema)扫描的文件个数。当数据集中的数据模式(schema)都是一致的情况下,指定该值为1能提高加载数据集的效率。默认值是-1,会扫描指定数据集路径下所有的文件,然后合并扫描到的数据模式(schema)。设置为0的时候会关掉自动模式识别,只有分区的信息会扫描出来。schema_conversion: 默认为null,当指定为string时会默认将csv的schema全部转化为string存储下来。
- 参数类型:
功能:从指定的目录加载所有的
csv数据集样例:
- 从路径
/dataset/csv下加载所有的csv文件,并且以year/month的子目录作为分区
SELECT * from load_csv('/dataset/csv', 'year/month')数据
/dataset/csv必须以pv的形式挂载到Kubernetes中,并且能被引擎找到。- 对于cardinality很大的csv文件,arrow的csv_loader会动态对前1M大小的做schema扫描,对于schema在1M之后的行数和前面schema不同的时候会出现错误(
CSV conversion error to null)。所以我们可以指定为string来防止此类错误
SELECT * from load_csv('/dataset/csv', '', -1, 'string')- 从路径
load_json
c++ table function函数签名:
SELECT * FROM load_json(path[, partitions, inspect_fragment_count])函数参数:
- 参数类型:
(string, string, int) path: 加载json数据集的路径,可以是单个文件的路径,也可以是文件夹,文件必须放置于${STONEWAVE_HOME}/var/external_data文件夹路径下。partitions: 指定json数据集的子目录为分区,例如year/month/day将会把目录结构为2020/11/16解析成为year=2020, month=11, day=16放在结果集中。inspect_fragment_count: 指定自动检测数据集模式(schema)扫描的文件个数。当数据集中的数据模式(schema)都是一致的情况下,指定该值为1能提高加载数据集的效率。默认值是-1,会扫描指定数据集路径下所有的文件,然后合并扫描到的数据模式(schema)。设置为0的时候会关掉自动模式识别,只有分区的信息会扫描出来。
- 参数类型:
功能:从指定的目录加载所有的
json数据集 (目前暂不支持嵌套的json)样例:
- 从路径
/dataset/json下加载所有的json文件,并且以year/month的子目录作为分区
SELECT * from load_json('/dataset/json', 'year/month')数据
/dataset/json必须以pv的形式挂载到Kubernetes中,并且能被引擎找到。- 从路径
load_arrow
c++ table function函数签名:
SELECT * FROM load_arrow(path[, partitions, inspect_fragment_count])函数参数:
- 参数类型:
(string, string, int) path: 加载arrow数据集的路径,可以是单个文件的路径,也可以是文件夹,文件必须放置于${STONEWAVE_HOME}/var/external_data文件夹路径下。partitions: 指定json数据集的子目录为分区,例如year/month/day将会把目录结构为2020/11/16解析成为year=2020, month=11, day=16放在结果集中。inspect_fragment_count: 指定自动检测数据集模式(schema)扫描的文件个数。当数据集中的数据模式(schema)都是一致的情况下,指定该值为1能提高加载数据集的效率。默认值是-1,会扫描指定数据集路径下所有的文件,然后合并扫描到的数据模式(schema)。设置为0的时候会关掉自动模式识别,只有分区的信息会扫描出来。
- 参数类型:
功能:从指定的目录加载所有的
arrow数据集样例:
- 从路径
/dataset/ipc下加载所有的arrow文件,并且以year/month的子目录作为分区
SELECT * from load_arrow('/dataset/ipc', 'year/month')数据
/dataset/ipc必须以pv的形式挂载到Kubernetes中,并且能被引擎找到。- 从路径
load_parquet
c++ table function函数签名:
SELECT * FROM load_parquet(path[, partitions, inspect_fragment_count])函数参数:
- 参数类型:
(string, string, int) path: 加载json数据集的路径,可以是单个文件的路径,也可以是文件夹,文件必须放置于${STONEWAVE_HOME}/var/external_data文件夹路径下。partitions: 指定parquet数据集的子目录为分区,例如year/month/day将会把目录结构为2020/11/16解析成为year=2020, month=11, day=16放在结果集中。inspect_fragment_count: 指定自动检测数据集模式(schema)扫描的文件个数。当数据集中的数据模式(schema)都是一致的情况下,指定该值为1能提高加载数据集的效率。默认值是-1,会扫描指定数据集路径下所有的文件,然后合并扫描到的数据模式(schema)。设置为0的时候会关掉自动模式识别,只有分区的信息会扫描出来。
- 参数类型:
功能:从指定的目录加载所有的
parquet数据集样例:
- 从路径
/dataset/parquet下加载所有的parquet文件,并且以year/month的子目录作为分区
SELECT * from load_parquet('/dataset/parquet', 'year/month')数据
/dataset/parquet必须以pv的形式挂载到Kubernetes中,并且能被引擎找到。- 从路径
xpath
c++ table function函数签名:
SELECT * FROM xpath(text, xpath, is_multi_value[, xpath, is_multi_value[, ...]])函数参数:
- 参数类型:
(string, string, bool, string, bool, string, bool, string, bool, string, bool, string, bool, string, bool, string, bool, string, bool, string, bool) text: 待解析的xml字符串。xpath: 指定解析xml的路径,参见这里。is_multi_value: 指定解析返回的字段是否为多值类型。
- 参数类型:
功能:将
text按照xpath指定的路径解析出对应的内容。样例:
- 从路径字面量中解析xpath对应的内容
SELECT *
FROM xpath('<books>
<book author="foo">java</book>
<book author="bar">python</book>
</books>', '/books/book', TRUE, '/books/book/text()', FALSE) t1- 对_message字段解析出xpath对应的内容,然后将解析得到的字段关联到原始表
SELECT x0.*
FROM bookstore APPLY xpath(
bookstore._message, '/bookstore/book/title/text()', TRUE, '/bookstore/book/title', FALSE) x0
lookup
c++ table function函数签名:
SELECT * FROM lookup(lookup_table_name[, lookup_key0, lookup_key1, ...])函数参数:
- 参数类型:
(string, string, string, string, string, string) lookup_table_name: 已定义的查找表(lookup table)的名字。lookup_key: 查找索引对应的字段;每个查找表的定义至少需要1个字段作为索引,最多可用5个字段作为索引;使用时若不指定对应的lookup_key,表函数将返回查找表内的所有数据。
- 参数类型:
功能:将给定索引字段对应的条目从查找表中取出;当一条索引对应多个条目时,只返回查找到的第一个。
样例:
- 用字面量查找
创建查找表
CREATE LOOKUP TABLE code_lookup WITH(KEYS='request_method')
AS SELECT request_method, code FROM load_csv('path/to/csv/file')得到查找表
code_lookup内容如下request_method code GET 200 POST 201 运行以下查询
SELECT * FROM lookup('code_lookup', 'GET')查询结果
request_method code GET 200 - 用数据集中的字段在查找表中进行查找,然后将查找得到的字段关联到原始表
创建查找表
CREATE LOOKUP TABLE code_lookup WITH(KEYS='request_method, datatype')
AS SELECT request_method, code, datatype FROM load_csv('path/to/csv/file')得到查找表
code_lookup内容如下request_method code datatype GET 200 access_log POST 201 access_log - 在非
APPLY场景下,不指定lookup_key,返回查找表内的所有数据
创建查找表
CREATE LOOKUP TABLE code_lookup WITH(KEYS='request_method, datatype')
AS SELECT request_method, code, datatype FROM load_csv('path/to/csv/file')得到查找表
code_lookup内容如下request_method code datatype GET 200 access_log POST 201 access_log 运行以下查询
SELECT * FROM lookup('code_lookup')查询结果
request_method code datatype GET 200 access_log POST 201 access_log - 在
APPLY场景下,不指定lookup_key,默认以APPLY之前的数据集中的同名字段作为lookup_key
创建查找表
CREATE LOOKUP TABLE code_lookup WITH(KEYS='request_method, datatype')
AS SELECT request_method, code, datatype FROM load_csv('path/to/csv/file')得到查找表
code_lookup内容如下request_method code datatype GET 200 access_log POST 201 access_log 运行以下查询
SELECT l.* FROM (SELECT 'GET' request_method, 'access_log' datatype) t
APPLY lookup('code_lookup') l等价于
SELECT l.* FROM (SELECT 'GET' request_method, 'access_log' datatype) t
APPLY lookup('code_lookup', t.request_method, t.datatype) l查询结果
request_method code datatype GET 200 access_log
如果当前 LOOKUP Table 中含有不只一个 CIDR 类型的 KEY,那么请保证任何一列 CIDR 内部都不会存在范围重合的情况。
我们每个 IP 只会匹配范围最小的 CIDR,比如:
| cidr_1 | cidr_2 |
|---|---|
| 10.10.3.0/24 | 10.10.1.0/24 |
| 10.10.3.128/25 | 192.168.0.0/16 |
如果使用:
| ip_1 | ip_2 |
|---|---|
| 10.10.3.129 | 10.10.1.1 |
是无法匹配到任何一行的,因为 10.10.3.129 只会匹配到 10.10.3.128/25,而不会匹配到范围更大的 10.10.3.0/24
了解更多查找表的信息和操作,请参考查找表
multi_lookup
c++ table function函数签名:
SELECT * FROM multi_lookup(lookup_table_name[, lookup_key0, lookup_key1, ...])函数参数:
- 参数类型:
(string, string, string, string, string, string) lookup_table_name: 已定义的查找表(lookup table)的名字。lookup_key: 查找索引对应的字段;每个查找表的定义至少需要1个字段作为索引,最多可用5个字段作为索引;使用时若不指定对应的lookup_key,表函数将返回查找表内的所有数据。
- 参数类型:
功能:类似于
lookup,将给定索引字段对应的条目从查找表中取出;不同的是,当一条索引对应多个条目时,将返回查找到的所有条目。样例:
- 用字面量查找
创建查找表
code_lookup内容如下request_method code GET 200 GET 202 POST 201 运行以下查询
SELECT * FROM multi_lookup('code_lookup', 'GET')查询结果
request_method code GET 200 GET 202
load_job_result
c++ table function函数签名:
SELECT * FROM load_job_result('search_job_id')函数参数:
- 参数类型:
(string) search_job_id: 已存在的查询任务的唯一标识ID。
- 参数类型:
功能:基于未过期的查询任务的结果做进一步查询。
样例:
- 获得查询任务的全部结果
SELECT * FROM load_job_result('fb4dc2d8-5e59-41d9-b57f-c554ce233f3a')
saved_search
c++ table function函数签名:
SELECT * FROM saved_search('saved_search_name')函数参数:
- 参数类型:
(string) saved_search_name: 已定义的预存查询(saved search)的名字。
- 参数类型:
功能:类似于
load_job_result,基于预存查询的缓存结果做进一步查询。样例:
- 获得预存查询缓存的全部结果
SELECT * FROM saved_search('saved_search_name')
current_job_meta
c++ table function函数签名:
current_job_meta()函数参数:
- 参数类型:
()
- 参数类型:
功能:显示当前查询的任务的元信息:查询任务id(job_id),查询时间范围开始(earliest_time),查询时间范围结束(lastest_time),查询开始时间(started_at)。 注:所有时间单位为microsecond的timestamp。
样例:
- 使用
outer apply获得当前查询的任务信息
SELECT * FROM generate_series(1,1,1) g outer apply current_job_meta() m|job_id|earliest_time|lastest_time|started_at| |-|-|-|-| |efc1a2ea-9d81-4f9f-b050-0d90036ebc65|1693212035454105|1693298435454109|1693298435476000|
- 使用
load_excel
python table function函数签名:
SELECT * FROM load_excel(excel_path[, worksheet_names])函数参数:
- 参数类型:
(string, string) excel_path: 加载的excel的文件路径,文件必须放置于${STONEWAVE_HOME}/var/external_data文件夹路径下。worksheet_names: 逗号分隔的Excel工作表(worksheet)名称
- 参数类型:
功能:从指定的文件路径加载Excel文件中的所有或者部分工作表。如果有多张工作表,工作表中的中的各个列会被合并为一张表。
样例:
- 从路径
/mnt/excels/example.xlsx下加载所有的工作表
SELECT * from load_excel('/mnt/excels/example.xlsx')数据
/mnt/excels/example.xlsx必须以pv的形式挂载到Kubernetes中,并且能被引擎找到。- 从路径
/mnt/excels/example.xlsx下加载指定工作表
SELECT * from load_excel('/mnt/excels/example.xlsx', 'Sheet3,Sheet5')通过指定逗号分隔的工作表名称
Sheet3,Sheet5,只有Sheet3以及Sheet5这两张工作表中的数据会被加载进来。- 从路径
parse_format
python table function- 函数签名:
parse_format(text, format) - 函数参数:
- 参数类型:
(string, string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)format: 按照format字符串指定的格式解析text的内容,获取新的字段。具体的format支持的格式和语法,参见这里
- 参数类型:
- 功能:
parse_format是一个表函数,用于从字符串中提取字段。将text对应的字符串按照format指定的格式进行解析。 - 样例:
- 对常量字符串解析,得到文件名和后缀名
SELECT * FROM parse_format('hello.doc', '{file_name}.{file_ext}')- 对常量字符串解析,提取有用的字段
user_id和login_time的信息
SELECT * FROM parse_format('User joel logs in at 9:59AM', 'User {user_id} logs in at {login_time}')
parse_grok
python table function- 函数签名:
parse_grok(text, grok_pattern) - 函数参数:
- 参数类型:
(string, string) text: 待解析的字符串(可以是一个字段的字段名,或者一个字符串常量)grok_pattern: 按照grok_pattern字符串指定的格式解析text的内容,获取新的字段。具体的format支持的格式和语法,参见这里
- 参数类型:
- 功能:
parse_grok是一个表函数,用于从字符串中提取字段。将text对应的字符串按照grok_pattern指定的格式进行解析。 - 样例:
- 对accesslog的
_message字段,使用grok提取ip信息
SELECT main._message, grok_table.*
FROM main
OUTER APPLY
parse_grok(main._message, '%{IPV4:ipv4}') as grok_table
where main._datatype='nginx.access_log' - 对accesslog的
parse_sql
python table function函数签名:
parse_sql(sql)函数参数:
- 参数类型:
(string) sql: 待解析的SQL语句(可以是一个字段的字段名,或者一个字符串常量)
- 参数类型:
功能:
parse_sql是一个表函数,用于解析SQL并返回SQL中包含的信息。 这一表函数会返回一张表,包含了三个字段:columns, 被解析SQL中访问到的所有字段名,每个字段名类似table.columntables, 被解析SQL中访问到的所有的表名query_type, 被解析SQL语句所属类型。根据具体的SQL语句,返回的类型可能是SELECT、UPDATE、INSERT、DELETE、CREATE TABLE、ALTER TABLE、unknown等。
样例:
- 对常量字符串解析,得到对应的SQL语句成分
SELECT * FROM parse_sql('SELECT u.id, u.name FROM users u')这里会返回一个表如下:
columns tables query_type ["users.id","users.name"] ["users"] SELECT - 对sql access log的
sql_statement字段,使用parse_sql提取访问的表名和字段名
SELECT sql_access_log.sql_statement, sql_info.*
FROM sql_access_log
OUTER APPLY
parse_sql(sql_access_log.sql_statement) as sql_info
faker
python table function- 函数签名:
faker(number_of_rows, fake_field_type) - 函数参数:
- 参数类型:
(int, string) number_of_rows: 需要生成的表的行数fake_field_type: 字段的类型,类型是一个字符串常量,具体支持的类型参见这里。多个类型的情况下用逗号分隔。
- 参数类型:
- 功能:
faker是一个表函数,用于生成指定行数的包含随机值的表。可以指定每一列的数据类型 ,列的数量取决于传递的列类型的参数个数。 - 样例:
- 生成一个有10行和2列的表,第一列是姓名,第二列是邮箱
SELECT * FROM faker(10, 'name,email')
summarize
python table function函数签名:
summarize(table_name)函数参数:
- 参数类型:
(table)
- 参数类型:
功能
summarize是一个表函数,用于生成表的描述性统计,包括数据集分布的中心趋势或形状的统计- 主要用于数值序列的分析,输出根据输入表的内容而变化。不统计空值。
- 对于数值列,结果统计包含count, mean, std, min, max, 25 percentile, 50 percentile, 75 percentile
- 对于字符串列,结果统计包含count, unique, top, freq
- 当数据源类型包含多种数据类型时,只统计数值列
样例:
- 统计main表
SELECT * FROM summarize(main)
pivot_table
python table function函数签名:
pivot_table(dataset_name, index_field, column_name, column_values[, fill_null])函数参数:
- 参数类型:
(table, string, string, string, double) dataset_name: 待转换的数据集名称,可以是CTE的名称,也可以是View名称index_field: 不会旋转的列,分组元素column_name: 需要旋转的字段名,旋转后作为列名,扩展元素column_values: 需要转换的字段值,旋转后填充到对应的列,聚合元素,可以选择多个值,需要用逗号分格。值得注意的是,当旋转多个字段值时,结果集合中的列名由{column_name}${column_value}来表达,具体请看示例fill_null:pivot结果中可能会存在一些空值,可以通过fill_null来填充这些空值,填充内容需为数值类型
- 参数类型:
功能:数据透视转换,改变数据源类型的版面布置,以便按照不同方式分析数据。是一种把数据从行的状态旋转为列的状态的处理。适用于画图。
样例:
准备样例数据,
WITH cte AS (
SELECT time_bucket, username, avg(speed) as avg_spd,
max(speed) as max_spd
FROM user_speed
GROUP BY time_bucket, username
)
SELECT * FROM cte转换前数据示例为:
time_bucket username avg_spd max_spd time_1 user_1 12 15 time_2 user_1 13 17 time_3 user_1 11 16 time_1 user_2 22 25 time_2 user_2 23 27 time_3 user_2 21 26 旋转单个字段值
avg_spd,SELECT * FROM pivot_table(
cte,
'time_bucket',
'username',
'avg_spd')透视转换后数据示例如下,这里旋转过来的字段名不带有字段值:
time_bucket user1 user2 time_1 12 22 time_2 13 23 time_3 11 21 旋转多个字段值,用逗号分隔开,这里选用了
avg_spd和max_spd,SELECT * FROM pivot_table(
cte,
'time_bucket',
'username',
'avg_spd, max_spd')透视转换后数据示例如下,结果集合中用
avg_spd$前缀代表用户的平均速度,用max_spd$前缀代表用户的最大速度:time_bucket avg_spd$user1 avg_spd$user2 max_spd$user1 max_spd$user2 time_1 12 22 15 25 time_2 13 23 17 27 time_3 11 21 16 26
unpivot_table
python table function函数签名:
unpivot_table(dataset_name, index_field, column_name, column_value_name)函数参数:
- 参数类型:
(table, string, string, string) dataset_name: 待转换的数据集名称,可以是CTE的名称,也可以是View名称index_field: 不进行行列转换的基column_name: 转换前的列名组成的列的新名称column_value_name: 转换前的列值组成的列的新名称
- 参数类型:
功能:逆透视转换,透视转换的逆操作
样例:
- 逆透视转换CTE
WITH cte AS (
SELECT username, speed, time_usage, distance
FROM main
)
SELECT * FROM unpivot_table(
cte,
'username',
'key',
'value')转换前CTE数据示例为:
| username | speed | time_usage | distance |
| -------- | ----- | ---------- | -------- |
| user_1 | 11 | 3 | 33 |
| user_2 | 13 | 3 | 39 |
| user_3 | 9 | 5 | 35 |
逆透视转换后数据示例为:
| username | key | value |
| -------- | ---------- | ----- |
| user_1 | speed | 11 |
| user_1 | time_usage | 3 |
| user_1 | distance | 33 |
| user_2 | speed | 13 |
| user_2 | time_usage | 3 |
| user_2 | distance | 39 |
| user_3 | speed | 9 |
| user_3 | time_usage | 5 |
| user_3 | distance | 35 |
transpose
python table function- 函数签名:
transpose(dataset_name, header_field_name) - 函数参数:
- 参数类型:
(table, string) dataset_name: 待转置的数据集名称,可以是CTE的名称,也可以是View名称header_field_name: 转置后的表头由转置前的某一列得到,可省略,默认为转置前的第一列作为转置后的表头
- 参数类型:
- 功能:表的转置。注意转置后的列不能包含不同数据类型的数据。
- 样例:
- 转置数据集main
SELECT * FROM transpose(main)- 转置CTE,并由列field_b作为表头
WITH cte AS (SELECT field_a, field_b, field_c FROM main)
SELECT * FROM transpose(cte, 'field_b')
jdbc
java table function函数签名:
jdbc(query, external_rdbms_jdbc_properties)函数参数:
- 参数类型:
(string, string) query: 查询关系型数据库的查询语句external_rdbms_jdbc_properties: 可以用两种表达形式,- json字符串。用来表达关系型数据库的JDBC数据源信息,其中
url和driver为必要信息。可选信息见JDBC driver properties - JDBC数据源名称。炎凰数据平台提供了配置文件
jdbc_data_sources.toml,用来持久化记录JDBC数据源信息。该配置文件放置于路径${STONEWAVE_HOME}/var/conf/custom/jdbc_data_sources.toml,可直接将JDBC信息存放在该配置文件中。url和driver为必要信息
- json字符串。用来表达关系型数据库的JDBC数据源信息,其中
- 参数类型:
功能:查询关系型数据库中的数据
配置文件
JDBC数据源信息(
url和driver为必要信息),例,# ${STONEWAVE_HOME}/var/conf/custom/jdbc_data_sources.toml
[data_source_name]
url = "jdbc url"
driver = "jdbc driver"
...
[data_source_name2]
...JDBC驱动
炎凰数据平台提供了几个默认的JDBC驱动,如下
com.mysql.jdbc.Driver // MySql
org.postgresql.Driver // PostgreSQL
org.h2.Driver // H2
oracle.jdbc.driver.OracleDriver // Oracle
org.hsqldb.jdbcDriver // HSQLDB
com.microsoft.sqlserver.jdbc.SQLServerDriver // SQL Server
org.mariadb.jdbc.Driver // MariaDB
com.clickhouse.jdbc.ClickHouseDriver // ClickHouse目前可以手动将合适的<example_database_driver.jar>驱动文件上传至
${STONEWAVE_HOME}/extensions/java_table_funcs/drivers例如上传一个客户商用数据库gbase9.5 drivergbase-connector-java-9.5.0.1-build1-bin.jar到指定目录。 然后运行table function。示例如下。SELECT * FROM jdbc('SELECT 1',
'{"url":"jdbc:gbase://127.0.0.1:5258/mydatabase",
"driver":"com.gbase.jdbc.Driver",
"user":"root",
"password":"root"}'driver信息可以通过文档查询该driverclass name或者可以通过jar tf <example_database_driver.jar>寻找。
JDBC数据类型映射
JDBC TYPE ARROW TYPE BOOLEAN
BITBool TINYINT Int(8) SMALLINT Int(16) INTEGER Int(32) BIGINT Int(64) NUMERIC(precision, scale)
DECIMAL(precision, scale)Decimal(precision, scale, 128) REAL
FLOATFloatingPoint(SINGLE) DOUBLE FloatingPoint(DOUBLE) CHAR
NCHAR
VARCHAR
NVARCHAR
LONGVARCHAR
LONGNVARCHAR
CLOBUtf8 DATE Date(DateUnit.DAY) TIME Time(TimeUnit.MILLISECOND, 32) TIMESTAMP Timestamp(TimeUnit.MILLISECOND, UTC_TIMEZONE) BINARY
VARBINARY
LONGVARBINARY
BLOBBinary Null Null Others Utf8 对于简单的数据类型,JDBC函数可以将查询结果类型直接映射到Array相应的类型。对于复杂的类型,需要额外的信息才能将类型映射到对应的Arrow类型,这很大程度取决于各个数据库的行为,或取决于用户期望。为了统一表达,复杂类型直接使用
STRING(UTF8)类型表达,如果需要更准确的类型,可以在炎凰数据平台中进行后续处理。样例:
使用JSON数据查询MySQL数据库中的websites表数据
SELECT *
FROM jdbc('SELECT * FROM websites',
'{
"url":"jdbc:mysql://localhost:3306/websites",
"user": "root",
"password": "passwd",
"driver": "com.mysql.jdbc.Driver"
}')使用数据源名称查询
配置文件示例
# ${STONEWAVE_HOME}/var/conf/custom/jdbc_data_sources.toml
[postgres_dsn]
driver = "org.postgresql.Driver"
url = "jdbc:postgresql://localhost:5432/postgres"
user = "postgres"
password = "mysecretpassword"查询示例
SELECT * FROM jdbc('select * from films', 'postgres_dsn')
当
query参数里面包含string的过滤的时候,要对过滤条件的string转义。SELECT *
FROM jdbc('SELECT * FROM websites WHERE foo = ''bar''',
'{
"url":"jdbc:mysql://localhost:3306/websites",
"user": "root",
"password": "passwd",
"driver": "com.mysql.jdbc.Driver"
}')
generate_time_buckets
c++ table function函数签名:
generate_time_buckets(start, end, span)函数参数:
功能:从起始时间戳开始,每过一个时间间隔便生成一个时间戳,直到结束时间戳为止。生成时间戳字段名为
_time。样例:
SELECT * FROM generate_time_buckets(TIMESTAMP'2000-02-01T23:00:00.000+08:00', TIMESTAMP'2000-05-1T00:00:00.000+08:00', INTERVAL'1month')_time 2000-02-01T23:00:00.000+08:00 2000-03-01T23:00:00.000+08:00 2000-04-01T23:00:00.000+08:00
通过 UI 界面管理表函数
进入数据目录页面以后,通过左侧导航栏里的"表函数"进入管理界面。在这里,用户可以用对表函数执行添加、修改、删除等操作。

不同于普通的函数,表函数的返回值是一个数据行(Row)的集合,这个集合表示一个二维表结构。 普通的标量函数的返回值是一个标量值(Scalar Value), 表函数(Table Function)可以看成是一个带参数的视图(Parameterized View)。
新建表函数
点击“表函数”页面左上方的黄色按钮。可以打开新建表函数的模态框,在模态框中输入表函数名,SQL查询语句以及函数参数(可选)点击确定,即可创建新表函数。
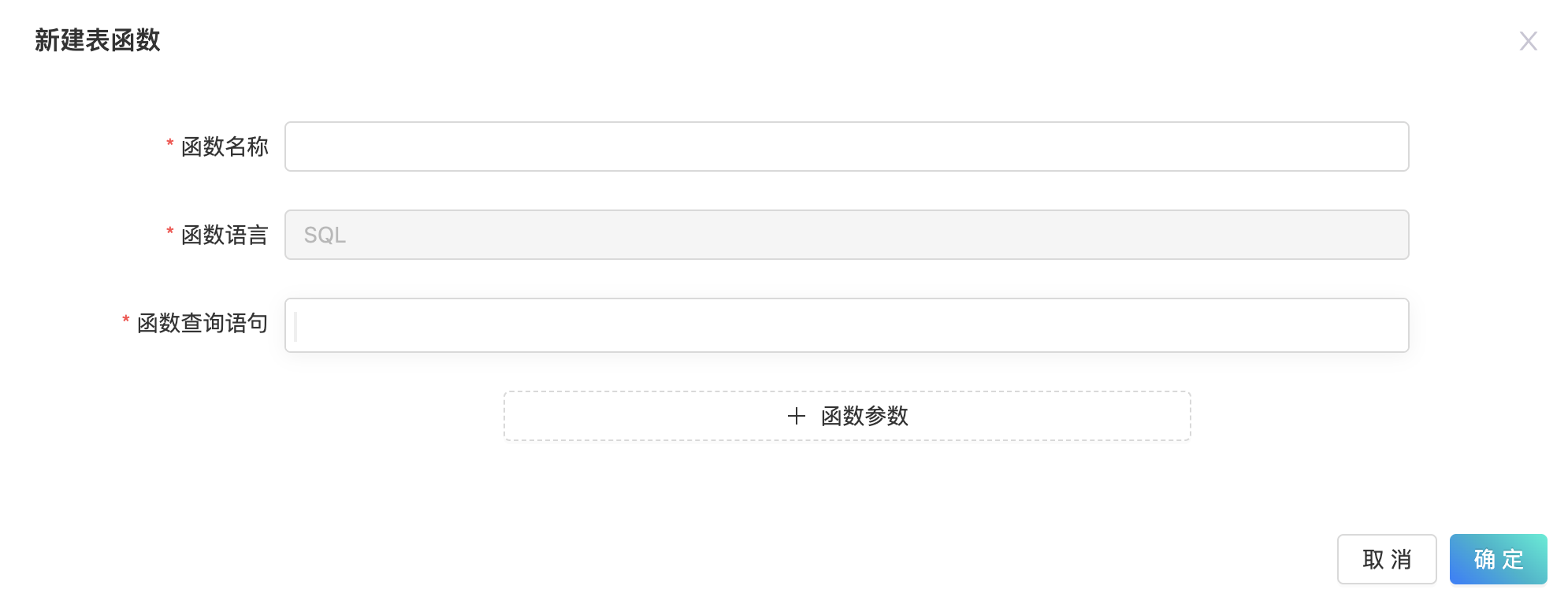
目前只支持新建SQL类型的表函数。
编辑表函数
点击表函数表右侧的编辑表函数按钮,即可打开编辑表函数的模态框从而更新表函数名称、查询值和和函数参数。
目前只支持编辑SQL类型的表函数。
删除表函数
点击表函数表格右侧的删除表函数按钮,即可删除该表。